entity と indices を用いてツイートをパースする
2019/11/18 13:56:542020/05/30 15:55:29
はじめに
まあ最終的な成果物と言えば
これだけなのだが、結構前から直したいと思っていた部分を倒せたので、乗りに乗って書き記しておきたいと思う
まず何
前提に関しては具体的な内容はどうでもいいので概要だけかいつまむと、自分が前から作って運用していた Twitter 関連の Bot におけるツイートの取得とパースにおいて、時々ぶっ壊れが発生していた。
- 例えば、同じハッシュタグが複数含まれていてそれがドカン
- 文章にするのが難しいが、単純な replace を行うと結果に問題が発生するのはわかっていただけると思う
- いやわかんなくて、わかんないだろ
- Markdown への変換を行っていたので、replace で最初のハッシュタグを置換した後そのハッシュタグが含まれる別のハッシュタグがあったりすると終わる(雰囲気伝われ)
#あいうえお #あいう
#あいうえお#あいう
- しばらく length で replace 順を変えたりして対策していたのだが、本質的な解決になっていない…(し、時々イレギュラーがちゃんと起きて変になってる)
これを解決するために意気揚々と indices を用いたパーサの制作に取り掛かったわけなのだが、結構色々これが難しかったので(頭が足りん)共有したい。具体的に言うと 1.5h 近くかかった
作る
まず一般的なパースは AST から始めるものなので(そうか?)ツイートのテキストをどうにかして構造にしたい
まずこれで結構悩んだのだが、結局以下の通りの方法を取った。
- Entities を全部ひとまとめの配列にする
parser.ts const entities = Object.entries(status.entities)
.filter(entity => entity[1])
.flatMap(([entityType, entityArr]) => {
return entityArr.map((entity: any) => {return {entityType, ...entity}})
}) as ({ entityType: string; indices: [number, number], [name: string]: unknown })[]- indices 始点をキーにした連想配列を作る
parser.ts const slices = Object.fromEntries(entities.map(entity => [entity.indices[0], entity]))- テキストを 1 文字つづ for で回して位置が連想配列に存在すればそこまでの文字を生文、そこから indices 終わりまでをエンティティとして扱う
parser.ts const parts = []
let current = 0
for (let i = 0; i < text.length; i++) {
if (i in slices) {
const slice = slices[i]
parts.push(text.slice(current, i).join(""))
parts.push(text.slice(i, slice.indices[1]).join(""))
current = slice.indices[1]
}
}
parts.push(text.slice(current).join(""))発生した問題点
まず indices のとおりに文字列をバラバラにする時点で結構難しかったのだが(上記のやりかたも結構苦しい、こういう書き方あるよ〜っていうのがあったら README にある連絡先に連絡してほしい)、なんか一部ツイートのパースにおいてめっちゃずれる場合が発生した(上げたコードにおいては修正済みのため発生しない)。
- こんな感じでずれちゃうのである
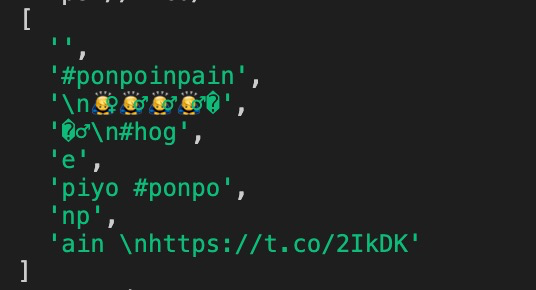
しばらく各種ツイートを取ってみてずれるツイートとずれないツイートを見比べてみたのだが、ふと絵文字が二文字に分裂していることに気づいた。
察しのいい方はなんか文字列のパースでめっちゃずれるの時点でピンときてそうなものだが、これはサロゲートペアのせいだった。
サロゲートペアって何
文字を類ずる特殊系に変形させたり、絵文字においては色・性別を変えたりする感じの拡張である。(追記: ここらへんかなり大雑把な解釈で通しているので厳密には違うかもしれない)
によると、UTF-16 だとビット数が足りなくて基本多言語面(U+FFFF)しか符号化できなかったのを、符号単位を2つ使って U+10FFFF まで表現できるようにした物。 https://twitter.com/rokoucha/status/1196824056722362369
拡張文字はスライスにおいて1文字で扱われるので、上記スクショのように full_text を直接スライスで切り出しているとガッツリハマる。
- (ZWJ や異体字セレクタは直前や直後の文字に作用し、リガチャーを作る制御文字。)
解法
切り出しに slice を使っていれば話は早くて、full_text を
Array.from()String.join("")- なぜ Array.from() で配列を作るとサロゲートペアが適切に処理されるかはわからないが、そういうものらしい…
によると、イテレーターで分解するときはコードポイントで分割(=UTF32)するから、とのこと
- この適切というのは単純に1文字として扱ってほしいパースしたい側の思う適切であり、サロゲートペアの1文字としてほしい開発者からすれば不適切であるが…まあ記事の本題には関係がない…
おわり
Scrapbox に書くと起承転結が雑でいいのがいいよね
- それは人によるか…
Generated from
entity と indices を用いてツイートをパースする
Caramelize - Made withCaramelizeand / Privacy